At first glance, frameworks like the EU AI Act put the primary burden of regulation onto artificial intelligent applications, according to the risks determined by the application area. This ought to imply that “foundation models” like its GPT series might be immune from regulation, as they’re offered as components for application developers, not as applications in their own right.
Indeed, OpenAI appears to have lobbied to get their components, such as GPT and DALL-E model versions, removed from automatic regulation.
“OpenAI has not previously disclosed its lobbying efforts in the EU, and they appear to be largely successful — GPAIs aren’t automatically classified as high risk in the final draft of the EU AI Act approved on June 14th.” (The Verge, 20th June 2023)
In other words, when developing a high-risk application such as one in hiring decisions, the liabilities are entirely placed on the application developer, and OpenAI escapes through its usual Limitations of Liability. The application developer’s liability may be at least tens of millions, where OpenAI caps their liability at $100.
I believe there is a good case to be made that OpenAI has consciously planned this go-to-market strategy as a means to offload risks onto arms-length entities, especially through its still-close links to Y Combinator. They gain the benefits of the revenue, while they escape the risks. It is organized irresponsibility in the sense of Ulrich Beck’s risk society. Is this valid? Obviously, I may be slightly partisan here, and I’ve framed the relationship accordingly. But, is there a solid reason why it is impossible for application developers to assume the whole risk of foundation models?
Yes, there is. The reason can be found in James Reason and his team’s work on accident causation at the University of Manchester. The best-known description of this is the ubiquitous “Swiss Cheese Model”.
Reason’s model describes a system as if it is a stack of slices of Swiss cheese. Each layer has some holes in it. One layer, obviously, has complete holes, so risks can pass straight through and turn into actual harms. But if we stack them together, two or three slices, so that the holes don’t line up, we end up with fewer gaps, and it is very much less likely that risks turn into harms.
When we design (and regulate) a system to be safe, we are creating these slices of cheese. We cannot expect a single protection to block all potential risks, but several layers of protection combined together can create a “strength in depth” effective barrier to harms, as shown in Figure 1 below. In this figure, I’ve shown the foundation model as a kind of sandwich between application layers. After all, the application will handle some risks. It should attempt to detect and resolve as many risks as possible early, and to manage some failures from the model itself. And with decent testing, it may do a decent job for many cases.
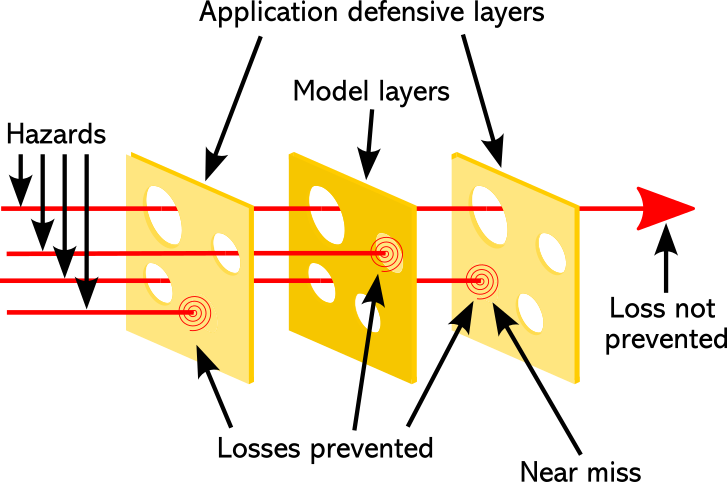
Reason’s model separates immediate causes from latent failures. Immediate causes the risky acts that can be linked directly to a harmful outcome, but not in themselves necessarily harmful. Latent failures – which can lie hidden indefinitely, and often have origins in management or organizational origins – contribute to the harmful outcome. For example, if management presses short timescales as preferable to safe deployment, it can lead to cutting corners in acquiring data, cleaning it, or revisiting the training data once harms become more apparent.
Foundation models limit regulation by the EU AI Act by insulating themselves entirely from immediate causes. This was, clearly, the primary aim of OpenAI’s lobbying. They like regulation, but only for other people. Because a foundation model is not an application in its own right, merely a component, any immediate causes are outside their scope. All that remains is latent failures. Worse still, because commercial foundation models are largely opaque black boxes, so there is no sensible way for an application developer to even discover where the latent failures might be, within the soup of billions of parameters.
But there are limitless opportunities for undetectable latent failure in any foundation model. For a start, the training data (which is enormous) will likely contain instances of racism, sexism, transphobia, and so on. Those can recur in responses and may not be detectable through filters in an application layer. Bias is also likely. Lack of fairness might well show up too.
Transparency is not a complete solution, either. Although the application developer may be fully transparent about their work, including, perhaps, additional models and fine-tuning – any foundation models they use are unlikely to be transparent in the same way. Their black-box status is a big factor in their economic appeal to AI investors. The more transparent they are, the more risks will be visible, and the harder it is to shed liabilities.
In effect, transparency is what lets us see the holes in a layer. Without it, the setup looks more like Figure 2 below, with a box obscuring the holes, so we cannot see in advance how (or even if) a defensive layer will work. We just have to let the hazards strike and see what happens. At best there might be hints about risk areas in the documentation. Not only does this offload risks onto application developers, it even limits their ability to test, because so many latent failures may be simply unknown to them.
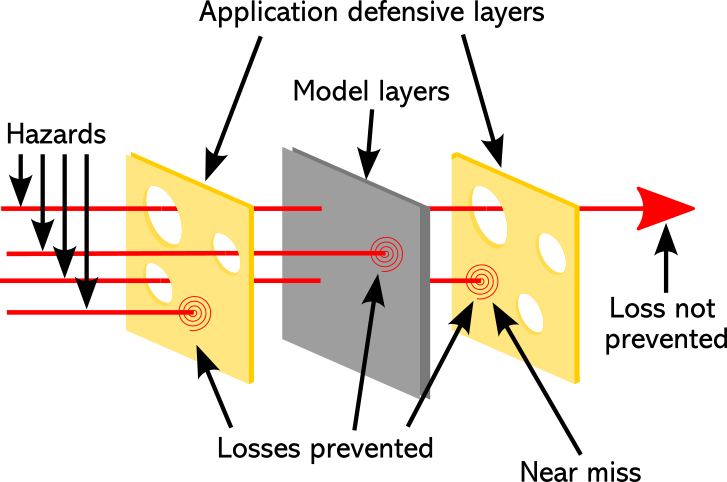
Note that even OpenAI has been transparent about some of these foundation model risks, although more on their process of prevention than on the actual risks. They do use filters on input. However, they are also open that there are known biases and stereotypes, against which there is much less mitigation in practice.
All in all, this is a wonderful deal for foundation model companies. They can download their risks onto application developers, without accountability – except when an application developer has the resources to punch through the liability exclusions in their terms and conditions. And in return, they get a lucrative source of revenue with virtually no risk – except, maybe, a reputational one. Even this is questionable – the same terms and conditions even prohibit using OpenAI’s name; this is a very one-sided deal. Meanwhile, the application developers have all the risks: of the market, of their own application, and of the latent failures in the foundation models. They even admit that, using language that echoes Reason’s model: “mitigating overreliance requires multiple defenses, and especially depends on downstream interventions by developers”.
At the very least, AI laws like the EU AI Act have to make a choice. They must either consider these risks of latent failures across all application areas an intrinsic characteristic of a foundation model, and maybe license them for specific areas, very much like drivers are licensed for particular classes of vehicle. Or, alternatively, they need to remove the protections of liability-shedding terms and conditions from foundation model vendors, so that application developers are not hung out to dry for any latent harms rooted in the foundation models they use.